How to set up a custom OpenAI-compatible Server in BoltAI
BoltAI supports a custom OpenAI-compatible Server such as an OpenAI proxy server, LocalAI or LM Studio Local Inference Servers.
Recommended Solution: Ollama
Ollama is a tool that helps us run large language models on our local machine and makes experimentation more accessible.
Follow this guide to install and use Ollama in BoltAI: https://docs.boltai.com/docs/start/use-another-ai-service
OpenAI-compatible server
There are a couple of options to run a local OpenAI-compatible server.
1. LM Studio
The easiest way to do this is to use LM Studio. Follow this guide by Ingrid Stevens to start.
👉 Running a Local OpenAI-Compatible Mixtral Server with LM Studio
2. LocalAI
LocalAI is another option if you're comfortable with docker and building it yourself. Follow their guide here:
How to use it in BoltAI
Go to Settings > Models, click the (+) button and choose "OpenAI-compatible Server"
Fill the form and click "Save Changes"
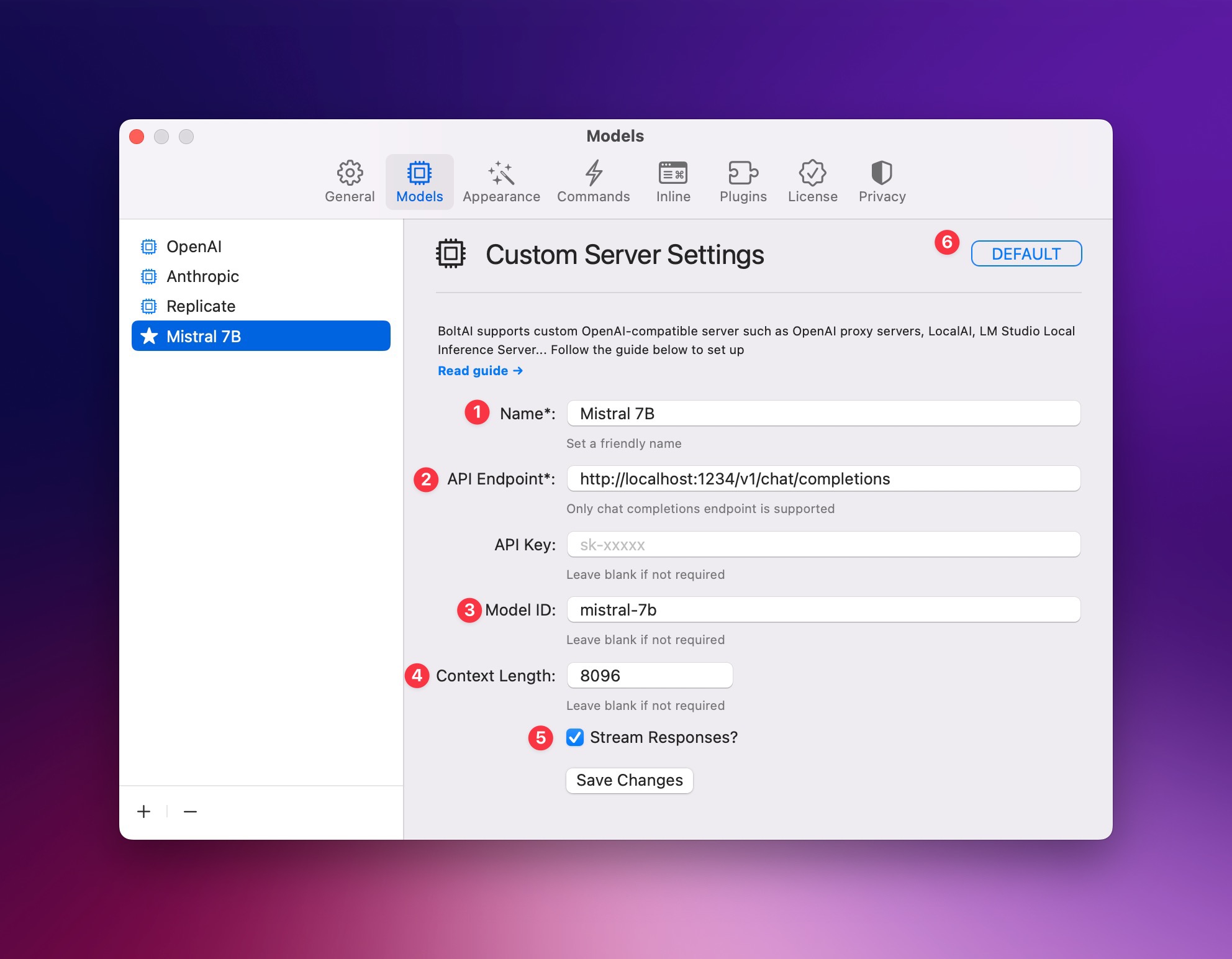
- Give it a friendly name.
- Enter the exact url for the chat completions endpoint. For LM Studio, the default is
http://localhost:1234/v1/chat/completions - (Optional) Enter the model id. This will be sent with each chat request (the params
modelin OpenAI API spec) - Enter the context length of this model. You need to refer to the original model to find this configuration. In LM Studio, find the "Context Length" configuration on the right pane.
- Enable streaming if the server supports it
Click "Save Changes".
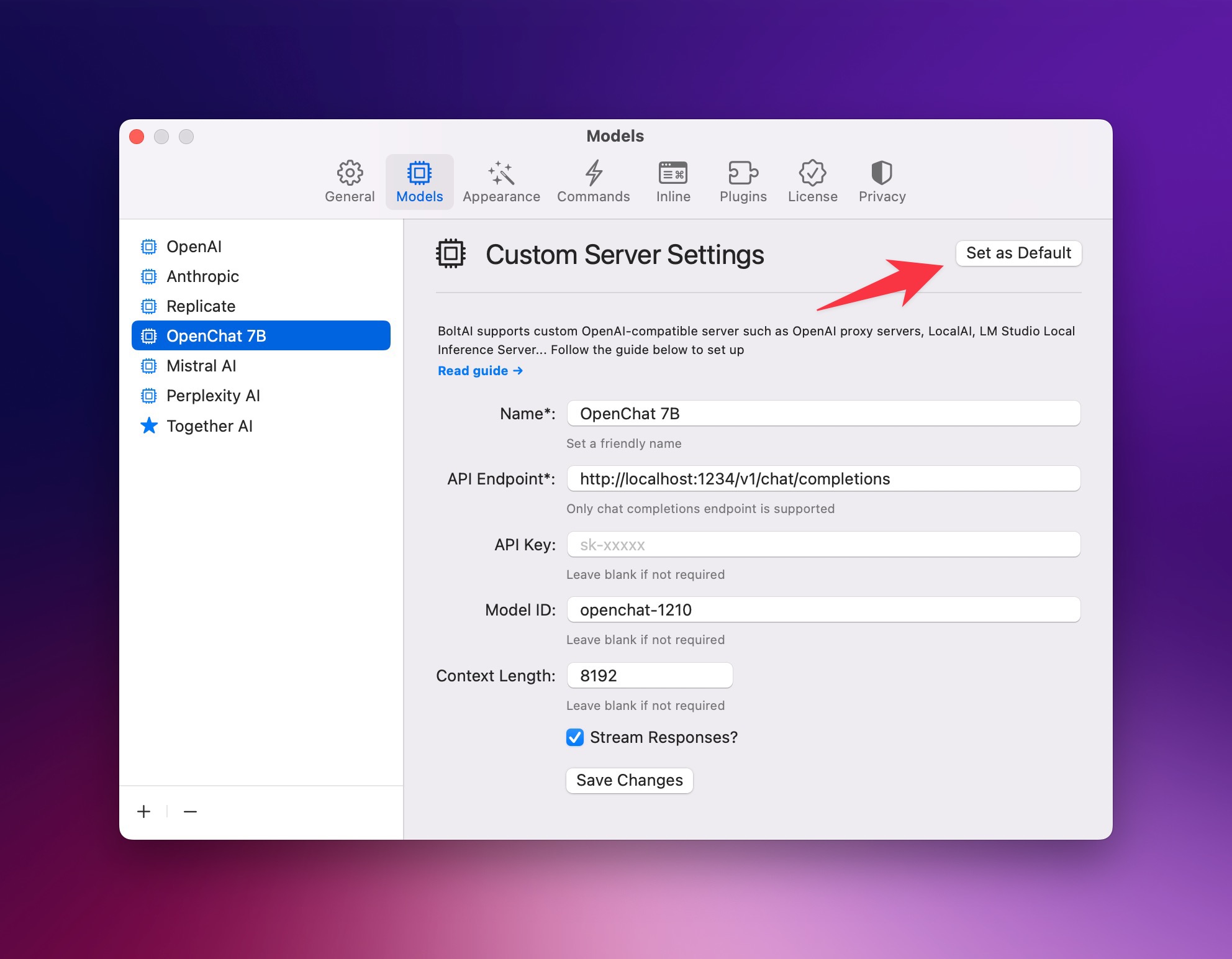
IMPORTANT: if you don't intend to use OpenAI, make sure to set this as default (6)
How to use AI Command with a custom server
This feature is still in beta. Please reach out if you run into any issue.
To use AI Command with a custom server, make sure you set it as the default AI service (screenshot below)
If you are new here, BoltAI is a native macOS app that allows you to access ChatGPT inside any app. Download now.
